[일주일프/02] g-export: 구글 문서들을 로컬에 다운받아주는 Claude Skill
g-export는 공개된 Google 문서(Slides, Docs, Sheets)를 로컬 파일로 다운로드하는 스킬입니다.
사용법:
- 명시적 호출:
/g-export - URL 감지: Google 문서 URL을 에이전트가 발견하면 자동으로 다운로드 제안
지원 포맷:
- Google Slides: pptx, odp, pdf, txt (기본: txt)
- Google Docs: docx, odt, pdf, txt, epub, html, md (기본: md)
- Google Sheets: xlsx, ods, pdf, csv, tsv (기본: csv)
저장 위치: ./g-exports/ 폴더 (원본 문서 제목을 파일명으로 사용)
주의사항:
- Sheets의 csv/tsv는 기본적으로 첫 번째 시트만 다운로드 (다른 시트는
gid파라미터 필요) - md 포맷의 경우 base64 이미지가 자동 제거됨 (이미지가 중요하면
docx나pdf사용)
작업 과정
며칠 전 고객사로부터 전달받은, 구글 문서 URL을 포함한 맥락을 Claude Code에 넣어서 컨설팅 설계를 도움받고 싶었습니다. 그런데 퍼블릭으로 공개된 URL이었는데도 fetch tool로는 문서 내용을 읽지 못하더군요. 그래서 구글 문서도구에 대해 가장 잘 알 만한 Gemini에게 이렇게 질의했습니다.
CLI를 이용해서 (즉 UNIX 명령어와 스크립트의 조합으로), Anyone Can View 권한인 구글 문서 URL의 내용을, 크레덴셜 확인 없이 마크다운 형태로 로컬에 저장하는 방법들을 제안해줘.
그랬더니 https://docs.google.com/document/d/{id}/export?format={format} 형태의 URL을 cURL 로 호출하면 파일을 저장하는 게 가능하지만, 마크다운은 안된다고 하더군요. 대신 docx 로 다운받은 다음 변환하라고. 그런데 Gemini가 가능하다고 얘기한 포맷들을 보니 구글 문서에서 직접 다운로드할 수 있는 포맷들과 상당부분 겹치더군요. 그리고 거기엔 마크다운도 있었습니다. 그래서 Gemini의 환각일 거라고 추측했어요.
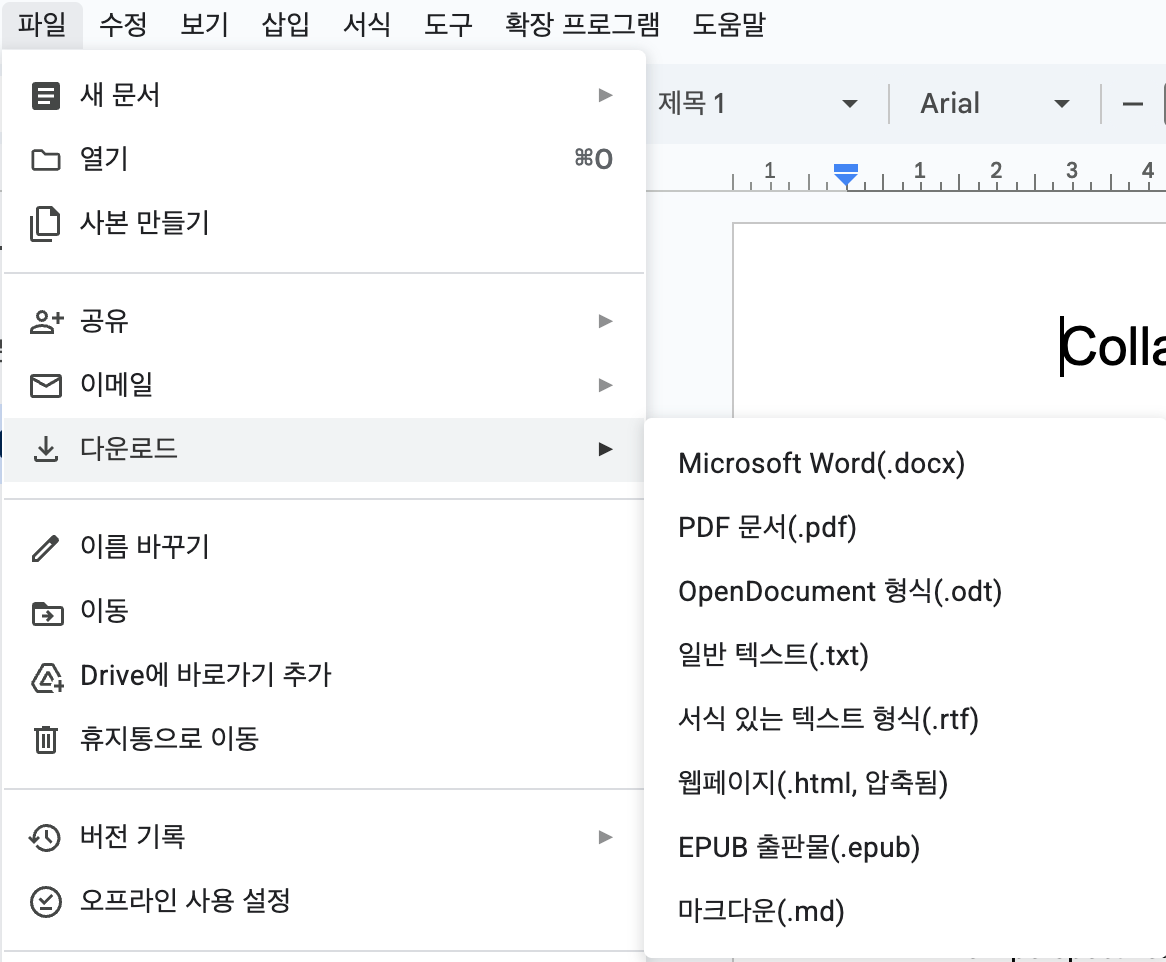
실제로 직접 마크다운 파일을 다운받으며 네트워크 요청을 살펴보니 Gemini가 이야기한 URL (/export?format=md)과 유사하게 다운로드 요청이 가는 게 보였습니다. 그걸 cURL 로 테스트해보니 터미널에서 다운로드도 가능했고요. 여기서부터 시작해 몇 번의 개선을 거치며 스킬을 구현했습니다.
- 구글 시트와 슬라이드로 확장: 구글 시트와 슬라이드는 독스와 URL 구조도 유사하고, 사용법도 유사합니다. 둘 다 다운로드 기능이 있고요. 아마 구글에서 설계할 때 공통 기능으로 다 빼놨을 거라고 보는데, 역시나 이들도 유사하게
/export엔드포인트를 지원하더군요. 그래서 스킬에서 3가지 타입을 모두 지원하게 했습니다. - 다중 탭 처리 및 포맷 선택: 슬라이드는 당연히 여러 장이고, 독스에도 탭이 있고, 시트에도 탭이 있죠. 제가 이 스킬을 만든 가장 주된 이유가 'LLM에게 넘기기' 였기 때문에, 가능하면 한번에 모든 정보가 텍스트로 주입될 수 있기를 바랐습니다. 물론
pdf나docx,pptx등도 앤트로픽이 스킬을 다 만들어뒀기 때문에 좀 더 Rich한 포맷으로 다운받아도 읽는 게 가능했지만, 다른 스킬을 연계해야만 하는 게 번거롭기도 하고... 필요시 사용자가 알아서 할 거라고 봤어요.- 슬라이드는 이미지로 다운받으면 '현재 선택된 슬라이드'만 저장되기 때문에 그 포맷은 그냥 지원하지 않기로 했습니다. 그리고 쉬운 분석을 위해 전체 슬라이드 내용이 잘 들어오는
txt를 기본 포맷으로 뒀어요. - 독스는 탭이 여럿이더라도
export가 기본적으로 한 파일에 취합해줬기 때문에 별 문제가 없었고, 기본 포맷으로는 당연히md를 선택했습니다. - 시트가 문제였는데, 텍스트로 읽기에는
csv가 가장 좋지만 이렇게 하면 첫 탭의 정보만 다운받아집니다. 그래도 주 목적이 분석이니만큼csv를 기본 포맷으로 두고, 대신gid를 URL에 같이 넣으면 다른 탭을 선택할 수 있다는 설명을 추가했습니다.
- 슬라이드는 이미지로 다운받으면 '현재 선택된 슬라이드'만 저장되기 때문에 그 포맷은 그냥 지원하지 않기로 했습니다. 그리고 쉬운 분석을 위해 전체 슬라이드 내용이 잘 들어오는
- 이미지 처리: 독스를 마크다운으로 다운받으면, 내부 이미지가 모두
base64문자열로 치환됩니다. 굉-장히 긴 문자열이 되고, 당연히 LLM에게는 쥐약이죠. 그래서 이미지 문자열을 전부 제거하게 했습니다. 참고로txt에서는 이미지가 아예 무시됩니다. 이미지가 필요하다면 사용자가 알아서 pdf나 html로 다운받을 거라고 가정했습니다. - 파일명 지정: 처음에는 파일명을 직접 지정하다가, 원본 파일명에 대한 정보가 내려올 거라고 생각해서 질의하니 역시 그랬습니다.
cURL에서-I옵션을 줘서 Content-Disposition Header를 가져올 수 있고, 이 정보를 디코딩하면 원본 파일명을 그대로 읽는 게 가능하더군요. - 한글 파일명 지원: 파일 이름이 한글일 때는 UTF-8 디코딩이 필요했습니다. 그냥 시켰더니
python3의urllib.parse라이브러리로 디코딩을 하던데, 외부 의존성을 최소화하고 싶어서 상의하니bash와printf로 대부분의 유닉스 환경에서 작동하도록 만드는 게 가능하더군요. 이러한 의존성 최소화 원칙을CLAUDE.md에 추가하기도 했습니다.
맺으며
지난 글에서도 언급했듯, 저는 LLM이 읽기 쉬운 포맷으로 문서를 쥐어주는 걸 중요하게 생각합니다. 요즘은 이게 대부분 "Claude Code가 UNIX 명령어와 스크립트만으로 URL을 읽을 수 있게 하자"로 치환됩니다. 이러한 작은 도구들을 하나둘 만들다 보면 워크플로우가 점차 매끄러워지며, 나아가 자동화될 수 있습니다.
이번에 만든 도구와 시행착오 모두 AI가 더 똑똑해지는 몇 달 뒤에는 무의미해질 수도 있다는 건 잘 알고 있습니다. 하지만 그렇더라도 '내 업무에서 불편함을 찾고 스스로 개선해나갈 수 있다는 자신감'은 오래도록 남을 거라고 생각해요.
Member discussion