OpenAI Multi-Agent Workflows 해커톤 참여 후기 (feat. OpenAI 엔지니어가 Codex를 사용하는 방법)
1월 20일, OpenAI가 공식 후원하고 Coxwave가 주최한 멀티-에이전트 워크플로우 해커톤에 코르카 동료 하동훈님과 함께 참여했습니다.

준비 과정
최근 코르카는 AI Science에 많은 관심이 있었기 때문에 과학 연구 가속화를 돕는 에이전트를 만들어보고자 했고요. AI 시대 이후로는 해커톤에 처음 참여해보는 거라서 준비를 많이 했어야 했지만... 실제로는 다른 급한 일들 처리하다 보니 거의 준비할 시간이 없었습니다. 😂
간신히 주말 + 전날 밤에 동훈님과 함께 회의하면서 큰 그림을 싱크했고, 이런 식으로 메타 전략을 짰어요.
- 50분마다 알림 맞춰놓고 회고를 하며 현재 상태와 배운 점을 공유하고, 방향 전환을 위한 기회로 삼자.
- (가장 큰 명세서이자 AGENTS.md에 들어갈 + README가 될) 문서부터 시작하기. 이 시스템은 누구의 어떤 문제를 푸는가? 그 문제는 왜 가치있는가? 데모 시나리오는 어떻게 되나(입력은 무엇이고 출력은 무엇인가)? 아키텍처는?
- 처음부터 살아있게 만들자. 가장 처음부터 (굉장히 얇은 상태로) 데모 시나리오가 가능한 상태로 만들고 여기에 하나씩 붙여나가자.
- Eval이 매우 중요. 에이전트에게 넣을 데이터의 품질은 어떻게 평가하고 개선할 것인가? 데모 시나리오의 성공 기준은 무엇으로 잡을 것인가? 각 에이전트의 성공 기준을 무엇으로 잡을 것인가? 각 기준을 어떻게 자동으로 평가하는가? (https://dspy.ai/ 를 쓰면 어떨까?)
OpenAI의 Agents SDK를 준비하면서 처음 써봤는데 한국어 문서도 있고, 아주 다양한 부분에서 사려깊게 구현되어있어서 놀랐습니다.
OpenAI 엔지니어가 Codex를 사용하는 방법
시작하기 전에 OpenAI의 솔루션 아키텍트인 Tyler Ryu께서 (다행히 한국어로) 유익한 발표를 해주셨어요. 발표자료가 슬라이드인 줄 알았는데 모든 게 Codex로 구현되어, 라이브 데모까지 가능한 웹사이트였다는 게 놀라웠습니다. 간단하게 요약해봅니다.
Codex 사용 패턴
타일러는 Codex를 주로 이렇게 쓰신다고 하더군요.
codex --yolo --search --enable collab
yolo: 권한 모두 허용해둔 것. 당연히 조심해서 써야 함.search: 기본적으로 codex는 웹서치가 막혀 있음. 이거 해야 열림.--enable: 베타 버전 기능들은 이걸로 켜야 함collab: 작업을 서브에이전트로 동작시키는 것.spawn키워드가 프롬프트에 있으면 작동함. 1/20 새벽에 추가된 기능.
참가자 질문 중 'Claude Code 대비 Codex가 뭐가 좋은가?' 가 재미있었는데요. 타일러는 어디까지나 개인 의견임을 강조하시며 이렇게 얘기하셨습니다.
- Codex가 실행 시간은 좀 더 길지만, 생산되는 코드 퀄리티가 조금 더 높은 느낌.
- 아주 거대한 저장소에서 잘 동작함. OpenAI에서 과학 연구도 다 Codex로 하고, 죄다 모노리포라서 clone 받으면 몇십GB쯤 되는데 그래도 잘 됨.
- 오토 컴팩션 성능이 좋아서 컨텍스트 걱정을 최근에 한 적이 없음. 10번 컴팩션돼도 잘 동작하더라.
- 명령을 굉장히 잘 따름. 좋은 명령 내릴 수 있다면 추천.
저는 다른 것보다 오토 컴팩션의 성능에 놀랐습니다. 마침, 관대하게도 모든 참여자들에게 OpenAI API 크레딧 $100과 ChatGPT Pro 1년 플랜이 지급되었습니다. 덕분에 오늘은 작정하고 Codex를 extra-high effort로 써봤고, 실제로 컨텍스트 제약이 별로 느껴지지 않았어요.
멀티-에이전트 워크플로우 패턴
또한 타일러는 OpenAI가 다양한 고객사에서 만나는 패턴을 6개로 정리해주셨습니다.
- Manager-Worker: 가장 일반적. Cursor에서 최근에 Codex 써서 웹브라우저 처음부터 만들었는데 그것도 이렇게 한 것. 오케스트레이터가 서브에이전트에게 작업 할당 후 전달받아서 병합
- Role-Specialized Swarm: Manager-Worker와 유사하지만 병합하기보다는 각자 다른 역할을 함. 유저가 다면적 보고서를 다 보고 종합할 수 있기 때문에 리서치에 유용함
- Debate / Adversarial: 서로 논의 + 역할연기 가능. 무한 논의 안 하게 종료 컨디션 필수(이건 다른 패턴도 유사). 법조계에서 유용하게 쓸 수 있음
- P2P Group Chat: 브레인스토밍에 좋음. 여기도 완료기준 등 제약 걸어놔야 함. 단순한 난상토론이 되지 않게, 서로가 서로를 멘션할 수 있게 하면 좋음
- Blackboard: 코드베이스 + Codex가 한 예시. 장기 실행 워크플로우. 스크래치패드랑 비슷함
- Planner-Executer-Verifier: 성공 선언 후 명시적 검증. 마지막에 validation해서 계속 점검. 점검하는 에이전트는 reasoning effort를 높이는 게 유리함. Verifier 루프에서 시간이 오래 걸릴 수 있어서, 시간이 안 중요한 케이스에서 쓰기 좋음
해킹!
7시간이면 그래도 뭔가 나오지 않을까? 했는데... 실제로 뭔가 나오긴 했습니다. (Top 5 수상은 하지 못했습니다ㅠ) 저희가 만들려고 한 것은 이런 녀석이었습니다.
자료 수집부터 검증, 시각화까지 스스로 수행하는 End-to-End Multi-Agent Workflow:
- Clarify: 모호한 업무 지시를 구체적인 리서치 주제로 명확화
- Plan: 기업 환경에 맞는 단계별 리서치 계획 수립 및 승인
- Search & Extract: Arxiv 등 신뢰할 수 있는 소스에서 심층 조사 및 정보 추출
- Verify: 추출된 정보의 출처와 사실 관계를 교차 검증 (Cross-Check)
- Synthesize: 리포트 자동 생성 및 시각화
핵심 차별점:
- Self-Healing Knowledge Graph: 단순 검색이 아닌, 정보 간의 인과 관계와 모순을 구조화하여 분석
- Enterprise-Grade Safety: 입력 데이터 보호 및 출력 결과의 신뢰성 보장 (Guardrails 적용)
- Full Observability: 에이전트의 모든 사고 과정과 데이터 흐름을 실시간으로 추적 가능
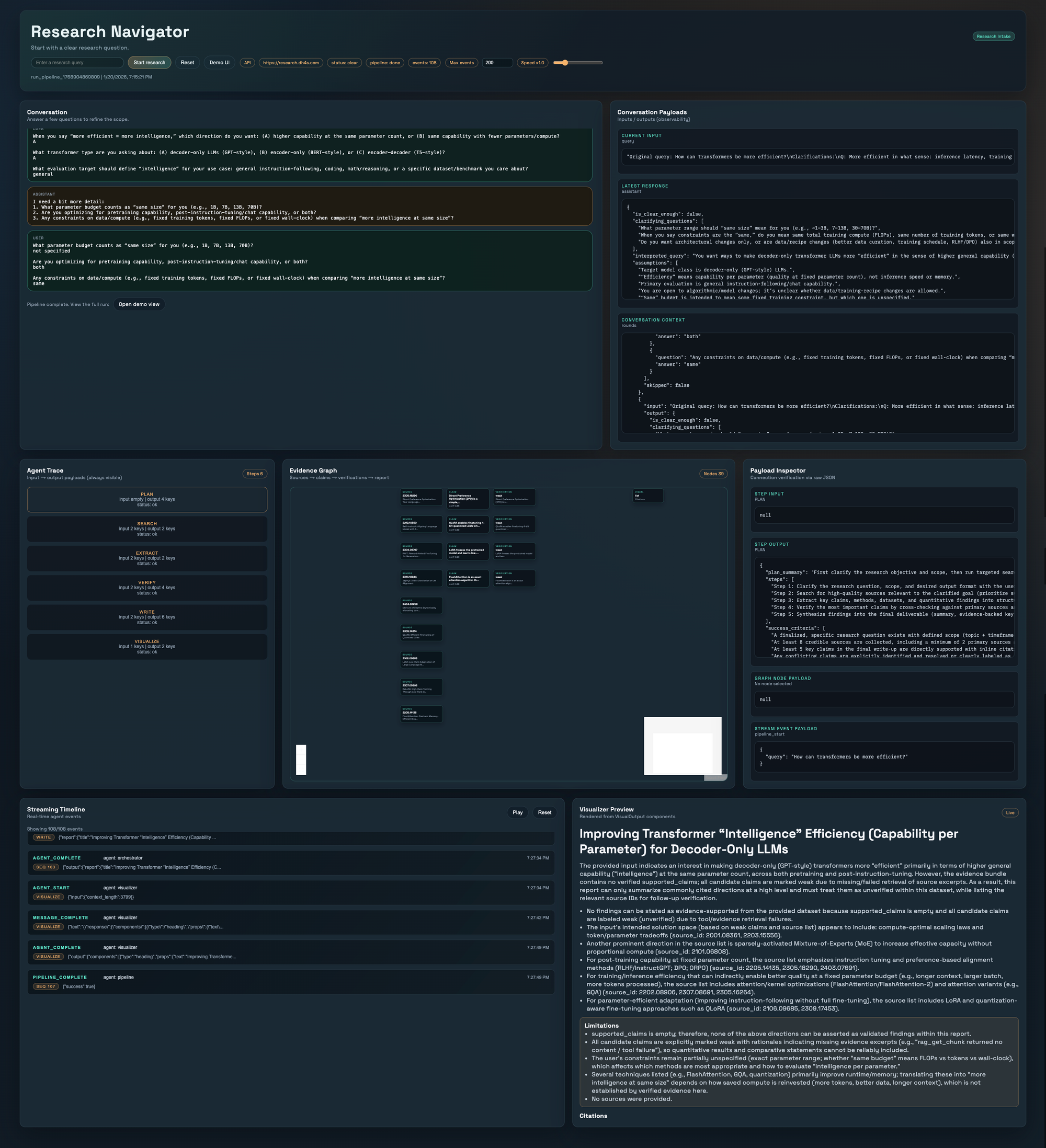
하지만 원래 원했던 스펙의 30% 정도는 구현하지 못했어요. 훨씬 멋진 시각화, 지식 그래프, 온톨로지까지 붙이고 싶었지만 현실은 제출 마감 1분 전에 마지막 커밋을 올릴 정도로 정신이 굉장히 없었어요. 두 사람이 역할을 아주 잘 나눠서 했었다보니, 한 명만 더 있었으면 더 잘 했을 것 같다는 생각이 들더군요.
미친듯이 집중해서, 정말 재미있는 시간이었습니다. 느낀 점들을 몇 개 적어봅니다.
잘 된 것
- 50분 - 10분 메타 전략이 초반에 아주 잘 작동했다. 나는 매번 하나의 피처를 완성했고, 나중에는 30분으로 이터레이션 시간을 줄였음.
- "README부터 시작하자"를 비롯해 '처음부터 데모 가능한 상태가 되게 하자'는 (적어도 CLI 레벨에서는) 아주 잘 작동했다. 덕분에 최소한의 안전장치가 첫 몇 분만에 마련된 상태에서 하나하나 붙여나갈 수 있었다. 그리고 덕분에 역할 분담도 잘 됐다. 나는 가장 바깥쪽을 만든 다음 앞뒤 에이전트를 만들어나갔고, 동훈님은 코어 로직 (Search - Extract - Verify 에이전트들) 을 구현하셨다.
- 극초기부터 모든 단계에서 테스트를 신경썼던 것도 좋았다. 데모를 비롯하여 모든 에이전트에서 success criteria를 고민시키고, 그걸 자동화 테스트로 만들고, 각 에이전트를 독립적으로 테스트 가능하게 만들었다. 덕분에 코드를 거의 단 한번도 보지 않고 대부분을 구현할 수 있었다. 모든 테스트에서는 observability를 최대로 강조했다. 이와 더불어 매 피처마다 코드리뷰를 시켜서 작은 리팩토링을 매번 하니 더 안심하면서 할 수 있었다.
- 말그대로 모든 프롬프트를 깃헙에 저장하면서 진행했고,
AGENTS.md를 점점 갈고닦았던 게 잘 먹혔다. 초반 이터레이션에서 "이번 세션에서 너와 내가 작업 스타일을 맞추기 위해 많은 대화를 했는데, 내가 네게 처음부터 어떻게 얘기했으면 이런 핑퐁이 줄었을까? 를 고민중이다. 생각해보고AGENTS.md에 넣을 만한 내용을 정리해서 추가해줘." 같은 걸 몇 번 했더니 이후는 점점 더 플랜을 그대로 승인하는 일이 많아졌다. - 웹 프론트엔드를 뒤늦게 붙였는데, Vercel의 React Best Pratices 스킬을 써서 구현시키니 상당히 예쁘게 구현을 잘 했다. 앞으로 더 많이 써봐야겠다는 생각.
잘 안 된 것
- 처음에 '데모 가능한 상태'를 CLI가 아닌 웹 프론트엔드로 상정했어야 했다. 서버 배포, 웹 배포를 너무 늦게 하니 마지막까지 CORS, 도커 캐시 등 다양한 문제가 생겨 쫄렸다.
- 우리는 Planner-Executer-Verifier 패턴을 쓴 셈인데, Verifier 루프가 도는 데 시간이 너무 오래 걸려서 직접 검증이 굉장히 힘들어졌다. 비록 우리의 실제 고객은 좀 더 오래 걸려도 품질이 높은 게 좋았겠지만, 데모에서는 루프 횟수의 상한을 더 줄이거나, 속도가 더 빠른 모델을 썼어야 했다.
- 프롬프트 품질을 더 신경쓰기 위해
dspy를 집어넣었지만 정작 시간이 부족해서 어떻게 동작하는지 거의 쳐다보지도 못했다. 이 시간에 UX 및 문서를 깎았으면 더 좋았을텐데. - 위에 연결되는데, 이 제품은 사실 코르카에게 실제로 의뢰가 들어와서 과거 PoC를 했고, v2도 의뢰받았던 고객사의 문제를 푸는 제품이기도 했다. 그런데 이런 이야기가 README에서 빠져있으니 '풀고자 했던 문제'의 매력도가 꽤 떨어져 보였다.
- AI Science 라는 주제는 코르카에서 관심있는 주제이긴 하나, 실제로 나와 동훈님에게 도메인 전문성이 깊은 주제가 아니었다. 그래서 evaluation 데이터를 만드는 것 또한 거의 LLM에게 맡겨야만 했다.
맺으며
비록 Top 5 수상이라는 결과는 얻지 못했지만 무척 가치있는 경험을 많이 얻었습니다. Codex의 컨텍스트 관리 능력과 구현 능력에 감탄했고, OpenAI Agents SDK는 개발자가 신경써야 할 것들을 대부분 간결하게 추상화해주었습니다. 이번에 받은 ChatGPT Pro Plan을 당분간 Claude Code와 함께 적극 활용해보려 합니다.
Member discussion